Knowledge Engineering for Agentic Systems
When I was Product Director for Cybersecurity at a large financial services company, I spent three months doing what felt like invisible work. We had migrated our Software Composition Analysis (SCA) from an aging on-prem tool to a modern SaaS platform, and I was steadily onboarding repositories into the new system. Hundreds of applications, one at a time. Tedious. Nobody was paying attention.
Then a critical zero-day vulnerability dropped.
A SWAT team formed across the company. Three response streams: Infrastructure, Applications, and Vendors. I was appointed responsible for the Applications stream. The other two streams started the way you would expect. Manual scanning. Spreadsheets. Lots of meetings where people asked each other what they owned and where the source code lived.
I opened the enterprise reporting console. I wrote a single query that selected every application with the affected dependency. Roughly 300 applications came back. I knew where the source code was. I knew who owned each one. I knew exactly who needed to fix it. Within days, I had reached out to every affected team with specific, actionable information. Then I ran the same report daily and watched the count drop. Two weeks later, my stream hit zero affected repositories. I gave my formal report-out to SWAT leadership. My work was done. The other two streams kept meeting for another month.
Those three months of unglamorous groundwork were knowledge serialization. I had converted scattered, volatile information (which applications use which dependencies, who owns what, where the code lives) into persistent, queryable artifacts. I just didn't have the vocabulary for it yet.
I see the same pattern every time a development team starts a new agent session without knowledge artifacts. The code from yesterday's session exists in Git. But the understanding of why it was built that way, what alternatives were rejected, what constraints apply, that knowledge died with the context window. They are the team with the spreadsheets. Not the team with the query.
Chapter 2 introduced context management as the agent's short-term memory. This chapter introduces Knowledge Engineering, the discipline of converting volatile session context into persistent, AI-readable knowledge that future agents and humans can consume. It completes the memory model and closes the feedback loop in the ADLC (the Agentic Development Lifecycle, the six-stage lifecycle introduced in Chapter 7 that replaces the traditional PDLC/SDLC split). Chapter 6 introduced Knowledge Engineering as the fifth skill, the shift from "code and forget" to "code and persist." This chapter shows how.
The Three-Layer Memory Model
Memory in agentic development isn't two layers. It's three. This is distinct from the architectural Three-Layer Model introduced in Chapter 2, which describes context management, persistent specs, and governance. The Three-Layer Memory Model zooms into the memory dimension specifically, showing how knowledge flows from volatile session state to durable project artifacts to cross-project wisdom.
Layer 1: Context (session-scoped). Working memory. Prompts, agent outputs, session state. The OOP parallel is the stack and heap, runtime memory that gets garbage collected. Context is born at session start and dies at session end. Chapter 2 taught how to manage it. This chapter teaches what happens to the valuable parts when the session ends.
Layer 2: Project Knowledge (repo-scoped). The bulk of this chapter. Historical specs, triad artifacts from the Governance Triad (PM, Architect, and Team Lead agents that form the governance layer) and Product Triad (Business User, UX/Product Designer, and Agentic Engineer that form the human strategy layer), knowledgebase learnings, bug documentation, architecture decisions, DevOps documentation. Everything that makes a specific project's codebase self-describing for the next agent session. The OOP parallel is the database or disk, persistent state that survives beyond any single process. This is where serialization happens. Volatile context gets distilled into durable, repo-scoped artifacts.
Layer 3: Practitioner Knowledge (practitioner-scoped). Not every lesson is project-specific. Some learnings, governance patterns that work, architectural anti-patterns to avoid, integration approaches that scale, transcend any single repository. Practitioner Knowledge captures these cross-project learnings and makes them available to future projects. The OOP parallel is shared libraries and service registries. No single application owns them, but every application benefits.
| Layer | OOP Parallel | AOD Equivalent | Scope | Lifecycle |
|---|---|---|---|---|
| 1. Context | Stack / Heap | Session context | Session | Minutes to hours |
| 2. Project Knowledge | Database / Disk | Repo artifacts (specs, Architecture Decision Records, context files) | Repository | Weeks to months |
| 3. Practitioner Knowledge | Shared library / Service registry | Cross-project knowledge | Organization / Practitioner | Months to years |
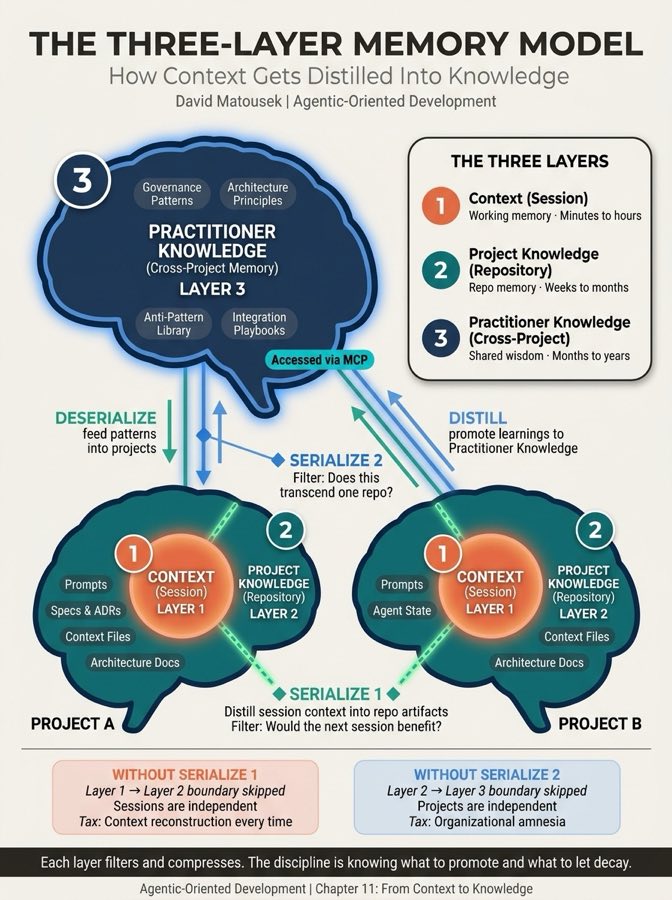
Here is how the layers connect. Raw session context (noisy, ephemeral) gets serialized into project knowledge (structured, durable). The highest-signal patterns from project knowledge get distilled further into Practitioner Knowledge (compressed, universal). Each layer filters and compresses. Not everything in context deserves to become project knowledge. Not every project lesson deserves to become cross-project knowledge. The discipline is knowing what to promote and what to let decay at each boundary. A useful heuristic for Layer 2 to Layer 3 promotion: if the same pattern solved a problem in two or more projects, it earns Practitioner Knowledge promotion.
I find it useful to think of it through an OOP lens. You wouldn't run a database application and throw away the database at the end of each session. But you also wouldn't keep every application's learnings siloed in its own database when the patterns apply across your entire portfolio. Objects in memory are working state. The database is persistent state. Shared libraries are reusable state.
Agentic development has the same three-tier architecture. Most teams manage context (Layer 1). Some persist project knowledge (Layer 2). Almost nobody systematically distills cross-project knowledge (Layer 3).
Chapter 7 established an important distinction. "Documentation tells humans what was built. Specs tell agents what to build." This chapter adds the third leg. Knowledge artifacts tell the next agent what exists, why, and how to extend it. And Practitioner Knowledge ensures those lessons compound across projects, not just within them.
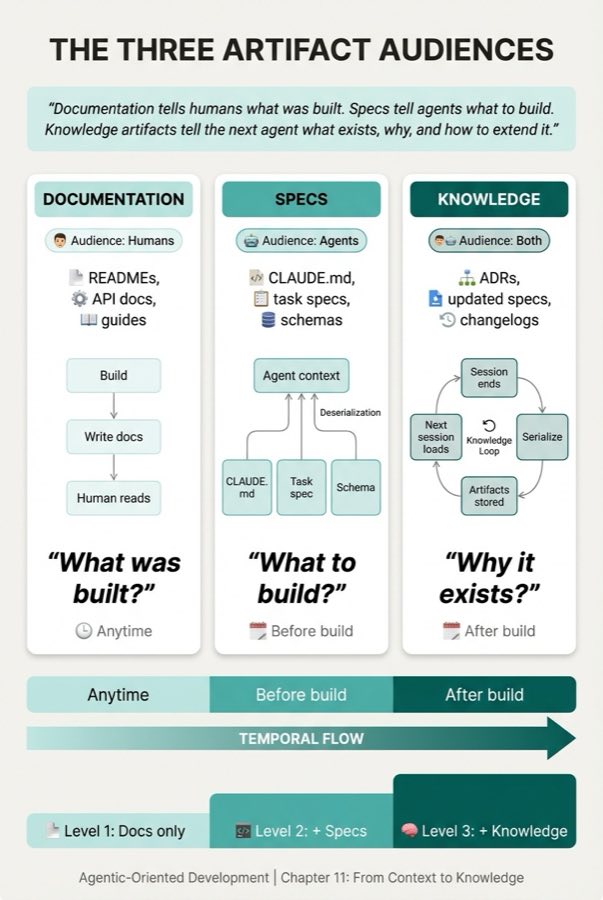
A note on Layer 3. Practitioner Knowledge is introduced here as a concept and a layer in the memory model. Chapter 12 (Connecting Agents Through the Model Context Protocol, or MCP) explores the protocol mechanics, including how a Practitioner Knowledge MCP server exposes cross-project knowledge to agents, how it integrates with the tool ecosystem, and how it connects project-scoped repos to practitioner-scoped learning. For now, just know that the layer exists and that MCP is what makes it queryable.
The Knowledge Loop
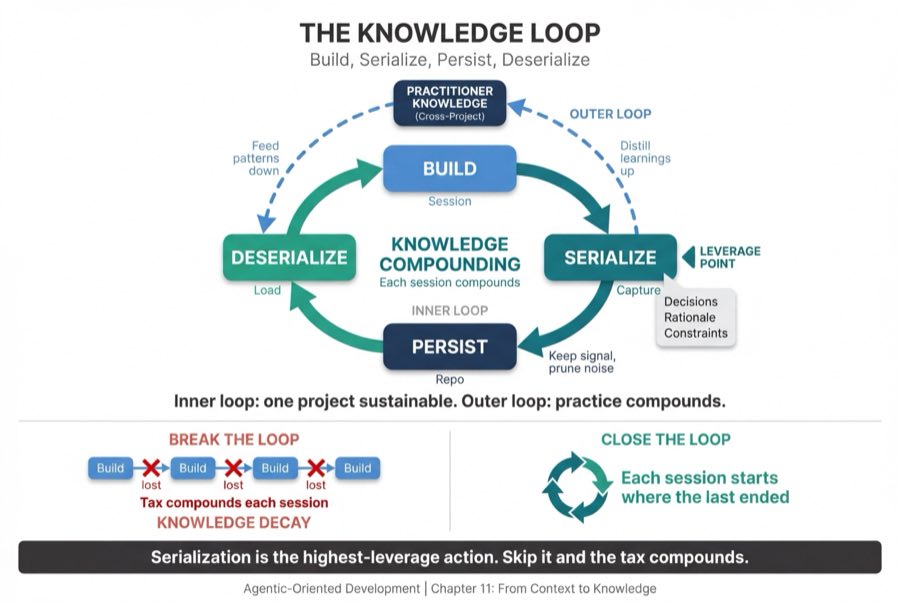
Build. Serialize. Persist. Deserialize. Build. This is the Knowledge Loop, the feedback mechanism that makes the ADLC sustainable. Without it, the lifecycle is linear. You build, and then you start over.
Let me define the terms through the OOP parallel that makes them precise.
Knowledge serialization is converting runtime context (what was learned during a session) into persistent repo artifacts. In OOP, object serialization persists state beyond process lifetime. Knowledge serialization persists understanding beyond agent session lifetime. When you capture an architecture decision, update a spec to reflect what was actually delivered, or document a constraint you discovered, you're serializing knowledge.
Knowledge deserialization is the reverse operation. Loading persistent knowledge back into agent context for the next session. This is what happens when an agent loads your project-level configuration file (CLAUDE.md in Claude Code, .cursorrules in Cursor, or equivalent), reads your specs, and processes your Architecture Decision Records (ADRs). It's rehydrating long-term memory into working memory.
The loop in practice is straightforward. After a build session, the agentic engineer captures what was built and why. Next session, the agent loads those artifacts and picks up where the last one left off. Without serialization, every session starts from scratch. Without deserialization, the knowledge exists but the agent never uses it.
Harness Engineering is proof that Knowledge Engineering works at production scale. OpenAI's Codex team built what they reported as over one million lines of production code across five months ("Harness Engineering: Leveraging Codex in an Agent-First World," OpenAI Engineering Blog, February 2026). Zero lines manually typed by humans. That isn't a demo or a proof of concept. It's a production system built entirely through agent-first development.
What makes their approach worth studying isn't the output. It's the infrastructure. OpenAI calls it "harness engineering," the practice of designing the environments, feedback loops, and documentation structures that surround an agent, rather than prompting the agent directly. Their principles map directly to the Knowledge Loop.
Their first principle is "What the agent can't see doesn't exist." Everything that matters lives in the repo. Markdown specs, schemas, execution plans, decision rationale. If it isn't in the repo, the agent can't use it. This IS knowledge serialization. Not as theory, but as a production constraint enforced across hundreds of pull requests.
Their fifth principle is "A map, not a manual." Their ARCHITECTURE.md serves as a bird's-eye view of the system. Navigable, not exhaustive. This validates garbage collection for knowledge. Persist the decisions and structure. Let the ephemeral details decay. Not everything from a session deserves to be preserved. The discipline is knowing which parts matter.
And then there is the feedback loop itself. OpenAI's team found that their most difficult challenges had shifted from writing code to designing the environments, feedback loops, and documentation structures surrounding the agent. Not prompting. Designing the harness. That is the Knowledge Engineering thesis in one sentence. The before (context engineering, Chapter 2) and the after (knowledge engineering, this chapter) together form the complete harness. OpenAI calls it harness engineering. In AOD terms, it's the Knowledge Loop in action.
The Knowledge Loop operates at two scales. The inner loop (Build, Serialize, Persist, Deserialize, Build) cycles within a project, session to session. The outer loop distills project knowledge into Practitioner Knowledge and feeds cross-project patterns back into new projects. The inner loop makes one project sustainable. The outer loop makes the practitioner's entire practice compound.
The loop describes the mechanism. Now let's look at what flows through it.
What Gets Serialized
Knowledge Engineering isn't "save everything." It's a discipline. Every artifact worth persisting falls into one of three categories, and each answers a different question for the next agent session.
| Category | Question It Answers | Examples | Temporal Lens |
|---|---|---|---|
| Product Knowledge | What is the product and how does it work? | Specs, architecture docs, system design, standards, DevOps procedures | Present / Future |
| Decision Knowledge | Why was it built this way? | ADRs, KB patterns, bug fixes, changelogs, inline rationale, sign-offs | Past |
| Configuration | How should the next agent behave? | Project config files, agent definitions, skills, commands, rules, constitution | Session setup |
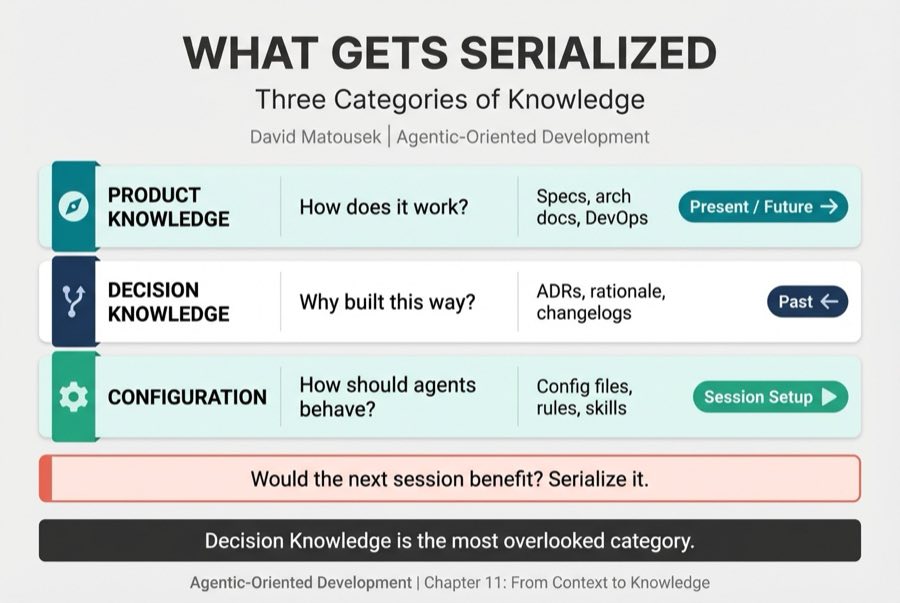
Product Knowledge answers: "What is the product and how does it work?"
This is the forward-looking category. Product vision, requirements, architecture documentation, system design, tech stack decisions, testing strategies, deployment procedures, and updated specs. Everything that describes the current state of what you're building. When specs drift during implementation (and they always do), the post-build spec reflecting what was actually delivered versus what was planned belongs here. If the delivered spec doesn't match the original, the next session will be working from a lie.
Product Knowledge also includes standards, conventions, and operational procedures. The Definition of Done. The git workflow. The CI/CD pipeline configuration. These describe how the product is built and shipped. They aren't lessons learned. They are the current rules of engagement.
Decision Knowledge is the most overlooked category. It answers: "Why was it built this way?"
This is the backward-looking category. ADRs that capture what was decided, why, and what alternatives were rejected. Knowledge base entries that document patterns discovered and bugs fixed. Root cause analyses. Changelogs that connect changes to the decisions that drove them.
I call this decision memory. It's the artifact type that prevents the next developer, human or agent, from re-exploring dead ends. OpenAI's harness engineering team embodies this. Their repo includes docs/design-docs/ with indexed, verified architectural decisions. Their agents "working on later tasks can reason about the decisions made in earlier tasks, the rationale behind them, and the current state of known technical debt, without any human needing to provide that context."
Here is what a serialized Decision Knowledge artifact looks like in practice. Imagine your agent session just resolved a recurring timeout issue by switching from synchronous to asynchronous API calls:
ADR-042: Switch payment gateway integration from sync to async
Status: Accepted Date: 2026-03-15 Context: Payment API timeout rate exceeded 2% under load, causing cascading failures in checkout flow. Decision: Replace synchronous calls with async queue-based integration. Added retry with exponential backoff. Alternatives rejected: (1) Increase timeout threshold (masks root cause). (2) Add circuit breaker only (reduces failures but doesn't eliminate them). Consequences: Checkout flow is now eventually consistent. UI must handle pending states. Next session should update the checkout spec to reflect async behavior.
Five lines. Thirty seconds to write at the end of a session. But the next developer or agent who touches the payment integration won't waste a session re-discovering the timeout problem or, worse, reverting to synchronous calls because they don't know why async was chosen.
This connects directly to Chapter 10. That test suite you're accumulating is Decision Knowledge about what to verify. Knowledge Engineering captures the complementary half: why the system was built this way.
One thing worth flagging on staleness. Stale Decision Knowledge is worse than missing Decision Knowledge. When a decision's context no longer applies, deprecate the artifact rather than leaving it to mislead future sessions. When artifacts conflict, the most recent wins because it captures why the prior approach was superseded.
Configuration answers: "How should the next agent session behave?"
This is the meta-level category. Your project-level configuration file (CLAUDE.md, .cursorrules, or equivalent). Agent definitions that describe roles and capabilities. Skills that encode reusable workflows. Commands that automate governance gates. Rules that control what context gets loaded and when. The project constitution that establishes non-negotiable principles.
Configuration is what gets deserialized first at session start. It shapes agent behavior before any Product Knowledge or Decision Knowledge gets loaded. When an agent session reveals that a particular approach fails or a specific constraint matters, that learning should become a Configuration update. But because Configuration shapes every future session automatically, this is a Governance Triad decision, not an agent decision, and it should pass through human review before commit. Flag proposed changes in the session's Decision Knowledge artifact so the Governance Triad can evaluate them during the next review cycle. A hallucinated constraint or a poisoned rule propagates silently into every downstream session.
The filter is simple. Would the next session, or the next developer, benefit from knowing this? If yes, serialize it into the right category. If no, let it go. Not all context deserves to become knowledge. Debugging steps, exploratory prompts, abandoned approaches. These are ephemeral. Persist decisions and rationale. Let debugging artifacts decay. This parallels Chapter 2's context hygiene, applied to the knowledge layer.
Serialization as a Security Boundary
One thing I want to flag because it connects to the work in Book 2. Serialization is the moment when volatile session context becomes persistent, readable files. This creates three risks that need explicit attention.
First, secrets must be stripped. Agent sessions routinely handle API keys, PII from test databases, and sensitive debugging output. If serialization is automatic or agent-driven, sanitization must be explicit at the serialization boundary.
Second, knowledge artifacts need integrity verification. A corrupted or hallucinated ADR that auto-loads into future sessions becomes a persistent source of wrong decisions.
Third, agent-generated knowledge can hallucinate confidently. An agent that "remembers" a constraint that never existed will propagate that false constraint to every future session through serialized artifacts.
Persist decisions and rationale. Never persist credentials, PII, or raw error logs containing sensitive data. And verify what gets persisted before trusting it blindly.
The Minimum Viable Knowledge Loop
Here is something concrete you can use tomorrow. Add this instruction to your project configuration or end-of-session prompt:
"Before ending this session, check each knowledge category: (1) Product Knowledge: did specs change from what was planned vs. delivered? Update them. (2) Decision Knowledge: capture any architecture decisions made and why, any constraints or edge cases discovered. (3) Configuration: flag any project config or rule changes for review if agent behavior should change next session. Do not include API keys, credentials, or PII in persisted artifacts."
One prompt. Three categories. Applied consistently, it closes the loop. That's all it takes to start.
But what happens when teams don't close the loop?
The Context Reconstruction Tax
Every session that skips serialization creates an invisible cost. I call it the context reconstruction tax, the price every future session pays when knowledge from previous sessions wasn't persisted.
It shows up predictably. The agent spends its first chunk of context window loading files and inferring intent that should have been stated explicitly. The developer spends minutes re-explaining context that was clear in the previous session. Features get rebuilt because nobody, human or agent, knew the prior version existed. In my experience, teams without serialization spend fifteen to thirty minutes per session re-establishing context that a five-minute serialization step would have preserved.
One skipped session is minor. A week of skipped sessions creates a knowledge debt that takes longer to repay than it would have taken to serialize in real time. This is technical debt's quieter cousin. Code debt accumulates in the codebase. Knowledge debt accumulates in the gaps between sessions. And unlike code debt, you can't grep for it. You only discover knowledge debt when someone rebuilds something that already existed or re-discovers a constraint that was already known.

I call this anti-pattern Knowledge Amnesia. Not the forgetting that happens when a context window resets. That's expected. Knowledge Amnesia is the organizational failure to serialize what was learned before the window closes. The code exists but nobody, human or agent, knows why it was built that way. The invisible cost compounds. Each session that doesn't persist knowledge increases the tax for all future sessions.
I don't know about you, but here is the mirror to the opening story. The teams with the spreadsheets during that zero-day response were paying the context reconstruction tax. They had the same information I did. It just wasn't serialized. Every meeting they held, every spreadsheet they built, was reconstructing knowledge that already existed somewhere, scattered across people's heads and unstructured documents. Your agent sessions face the same choice. Serialize what matters, or rebuild it every time.
And across projects, the tax multiplies. Without Practitioner Knowledge (Layer 3), every new project pays the reconstruction tax not just for its own sessions, but for lessons already learned in other projects.
What's Next
The developers who build knowledge loops will compound their expertise across every project they touch. Everyone else will keep starting from scratch, wondering why the tenth project feels as hard as the first.

This chapter introduced Practitioner Knowledge as the third memory layer, the place where cross-project knowledge lives. But a question remains. How does an agent in Project B access lessons learned in Project A? How does cross-project knowledge become queryable rather than just conceptual?
Through MCP.
Coming next: Chapter 12 goes deep on the Model Context Protocol as the layer that connects agents to tools, data, and each other. Chapter 3 introduced MCP as "the REST API moment for agents." Chapter 12 explores how a Practitioner Knowledge MCP server makes cross-project knowledge accessible at query time. The five skills equip the individual practitioner. Practitioner Knowledge extends learning across projects. MCP is the protocol that makes it all connectable.