Part 8 of the AOD series
I was head of mobile at TechLok, a startup building mobile security. This was 2012, before anyone had figured out how to protect phones from loss and theft at scale. GPS tracking existed but battery life was terrible. Remote wipe existed but users hated losing everything. The answer was not obvious.
I recruited three mobile developers through networking. Two iOS specialists and one Android specialist. Dozens of one-on-one conversations over a month to find people who could explore without a map. The challenge wasn't building something. The challenge was coordinating different capabilities toward an undefined solution.
My approach was to split the team into pairs running in parallel.
Team 1, which I led, built Bluetooth-based phone locking. Proximity detection using a paired device. When your phone lost connection to the secondary device, it locked. The mechanism worked. But the user experience required carrying two devices. That was a dealbreaker.
Team 2 built accelerometer-based user identification. Machine learning in the cloud analyzing walking patterns to distinguish the phone's owner from a thief. The identification was elegant and frictionless. But they had no locking mechanism. Knowing who held the phone didn't stop the wrong person from using it.
Neither team delivered a complete solution. Both delivered pieces of one.
The orchestrator's decision wasn't "which team won?" It was "what is the best combination?" I brought both teams together. We combined Team 1's locking mechanism with Team 2's identification algorithm. The lock triggered when the accelerometer detected an unfamiliar walking pattern. No second device needed. No manual intervention.
TechLok 1.0 won $20,000 in the NH Startup Challenge. We became MassChallenge finalists. And I learned something that applies directly to orchestrating AI agents today.
That startup team was a multi-agent system before the term existed.
Specialists with different capabilities running in parallel. An orchestrator who combined outputs instead of picking winners. The team composition mattered more than any individual contribution. Today, coordinating AI agents follows the same pattern. The orchestrator decides who does what, how long they run, and when to combine their work.
Let me break down exactly how that works, starting with the most fundamental decision.
Agent vs. Subagent: The Decision That Shapes Everything
Chapter 7 ended with a promise: the difference between "agent" and "subagent" is not semantic, it is structural.
Agents are persistent. They retain context across multiple tasks. They communicate directly with peer agents. Think of a PM agent that remembers the PRD decisions during implementation. Or an Architect agent that carries architectural constraints across checkpoints. The session stays alive. The context accumulates.
Subagents are ephemeral. They are scoped to a single task. They return summarized results to their caller. Then their context is discarded. Think of a backend-engineer agent that implements one API endpoint and reports back. Or a tester agent that runs a specific test suite and returns pass/fail. Spawn, execute, return, discard.
The OOP parallel is precise.
Agents are long-lived service objects. In OOP terms, think singletons or injected dependencies, objects that stay alive and retain state across method calls. Instance variables hold accumulated context. Subagents are method-scoped locals, objects created inside a function, used once, then garbage collected. Return values go back to the caller. No persistent state.
Put simply, agents are team members who stay on the project and accumulate knowledge. Subagents are specialists called in for one job, then released.

One important distinction from the OOP analogy. Agent "persistence" is session-scoped, meaning the agent stays alive for the duration of a workflow or project session, not permanently stored like a database record. It is closer to an application-scoped object than a true singleton across processes.
Stop thinking about "chatbots."
Start thinking about service objects versus method locals. If you wouldn't make a variable global, don't make that agent persistent.

The decision framework is simple. Does this role need to remember, or does it need to execute?
If the role needs to remember context across tasks, make it an agent. If it needs isolated execution, make it a subagent. When a role needs both, make it an agent that delegates to subagents.
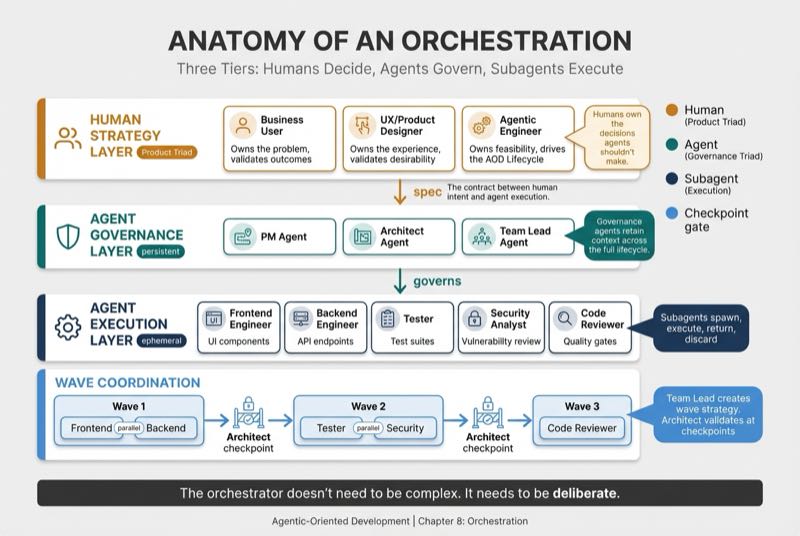
The Governance Triad I introduced in Chapter 2 maps naturally here. PM, Architect, and Team Lead are governance roles. They need persistence because they carry context across the full lifecycle. The PM retains product vision from PRD through implementation. The Architect carries architectural decisions across checkpoints. The Team Lead tracks progress across all phases.
Specialist roles are different. Backend-Engineer, Tester, Security-Analyst. These are execution roles. They need isolation and focus. They don't need to remember what happened in earlier phases. Isolation is a feature, not a limitation. The Security-Analyst should not be influenced by prior conversations when reviewing code for vulnerabilities.
Remember the SaaS security tool from Chapter 2, where the backend and frontend agents never connected? That failure was partly about context management. But it was also about making everything ephemeral. No persistent governance to hold the project together across phases.
The anti-patterns are predictable. Making everything an agent wastes tokens and risks context pollution. Making everything a subagent forces re-establishing governance context at every checkpoint. The best systems mix both types. The orchestrator decides which nodes need persistence and which work as fire-and-forget.
At TechLok, I was the persistent agent. I carried the product vision and customer requirements across both teams throughout the exploration phase. The paired teams were subagents. Scoped to their exploration, reporting results back to me. The mix was what made it work.
But this governance layer raised a question I did not see until someone pointed it out. I had been refining the model for months. PM Agent, Architect Agent, Team Lead Agent overseeing specialist subagents. A friend looked at the diagram and asked one question. "Where's UX/UI in this?"
My first instinct was to add a UX agent. Then I realized that was wrong. A UX agent can check contrast ratios and generate wireframes. It cannot sit across from a frustrated user and understand why a workflow feels broken. That requires human empathy, not token processing.
So I added a human strategy layer above the agent governance layer. I call it the Product Triad. Three humans who own the decisions agents should not make. A Business User who owns the problem. A UX/Product Designer who owns the experience. An Agentic Engineer who owns feasibility. The Product Triad produces a spec. The spec becomes the contract the Governance Triad enforces. Subagents execute within those boundaries.
This is also why I renamed the agent layer. In Chapters 1 through 7, I called the PM, Architect, and Team Lead the "Product Triad." But agents don't own the product. Humans do. The agent layer governs execution. So the agent triad becomes the Governance Triad, and "Product Triad" goes where product ownership actually lives, with the humans.
The full model is three tiers. Humans decide. Agents govern. Subagents execute.
Context Loading Control Modes: Who Decides What the Agent Sees?
Thoughtworks' Birgitta Böckeler calls this "Context Engineering," and I have found her distinction of control modes to be the single most overlooked decision in agent design.
Chapter 4 identified four types of inherited capability. CLAUDE.md, Tools and MCP servers (external services that provide tools to agents at runtime), Skills, and Hooks (event-triggered automations that fire deterministically at specific lifecycle points). But there is a deeper question those types answer.
When an agent needs context, who decides what it gets?
This is not a configuration detail. It is a security and reliability decision.
Three control modes define who is in charge:
| Mode | Who Decides | Chapter 4 Equivalent | Trade-off |
|---|---|---|---|
| LLM-controlled | The agent itself decides what context to load | Skills | Maximum flexibility, minimum predictability |
| Human-controlled | The user explicitly triggers context loading | Slash commands | Maximum certainty, minimum automation |
| Agent-software-controlled | Deterministic triggers load context automatically | Hooks | Predictable behavior, no manual intervention |
Each mode carries a distinct security risk. LLM-controlled context loading risks data leakage because the agent decides what to request, and it may pull sensitive information that wasn't intended for that task. Human-controlled risks bottlenecks and human error, but the attack surface is smallest. Agent-software-controlled risks rigidity, because deterministic triggers can't adapt when the context a task actually needs changes.

The orchestrator's role is designing which control mode each agent in the system uses. This is a per-agent decision, not a system-wide setting.
In a high-trust, exploratory task like research or creative writing, LLM-controlled context loading makes sense. Let the agent decide what it needs. In a compliance-critical task like security review or deployment, you want agent-software-controlled. Hooks (think pre-commit scripts or CI/CD event triggers) fire automatically. No agent discretion about what context to load. In a sensitive task where human judgment matters, like architecture decisions or customer-facing changes, human-controlled keeps the human in the loop.
This connects directly to Chapter 2's context pollution problem. Instead of hoping the context window doesn't fill up, you enforce who is allowed to fill it. Context loading modes are the architectural solution.
Once you know who controls context for each agent, the next question is how those agents are arranged to work together.
Architecture Patterns: From Single Agent to Multi-Agent Systems
At TechLok, I made architecture decisions instinctively. I split the team into parallel tracks, kept myself as the coordination point, and merged results at the end. I now recognize that as hierarchical plus parallel architecture. Here is how those patterns break down across the autonomy spectrum, and when to choose each one.
Anthropic's "Building Effective Agents" research identifies three levels of autonomy for agent systems.
| Level | Autonomy | When to Choose |
|---|---|---|
| LLM Workflow | Zero (fully orchestrated) | You need deterministic, repeatable results. Compliance-critical paths, regulated pipelines, anything where the same input must always produce the same sequence of actions. |
| Agentic Workflow | Low (orchestrated with detailed prompts) | Most development work. You want the agent to reason within boundaries you set, with checkpoint gates for validation between phases. Start here if you are unsure. |
| AI Agent | High (autonomous, objective-only) | Exploratory research, creative tasks, problem spaces where you can't predict the steps in advance. Give the agent a goal and trust it to find the path. |
Most teams should start with agentic workflows, not fully autonomous agents. Prioritize orchestration over autonomy. Move deterministic logic to orchestration layers for predictability.

Single agent patterns form the foundation.
Tool-using agents plan actions and use tools to execute. Choose this when the task is well-defined and the available tools cover the full scope of work.
Human-in-the-loop agents add approval workflows before execution. Choose this when actions are high-stakes, irreversible, or affect production systems.
Dynamic sub-agent spawning means the orchestrator invokes subagents based on task analysis. Choose this when the number or type of specialists needed isn't known until runtime. This is where the agent versus subagent decision meets architecture in practice.
Multi-agent patterns scale coordination. Sequential architecture means one agent clarifies requirements and a second agent executes. Choose sequential when each phase produces artifacts the next phase consumes. Hierarchical plus parallel means an orchestrator dispatches multiple specialists working simultaneously. Choose this when tasks are independent but need a single coordination point. At TechLok, Team 1 and Team 2 running in parallel was effectively Wave 1 of that manual orchestration.
Wave-based execution is the model behind hierarchical plus parallel. You group independent tasks into waves, run each wave in parallel, and gate the transition between waves with a checkpoint. Orchestration coordinates the waves.
Here is what a minimal orchestration definition looks like in practice:
orchestration:
governance:
pm-agent:
type: persistent
context-loading: human-controlled
role: "Validate output against PRD requirements"
architect-agent:
type: persistent
context-loading: agent-software-controlled
role: "Enforce architecture decisions at checkpoints"
team-lead-agent:
type: persistent
context-loading: agent-software-controlled
role: "Create wave strategy, assign agents, validate execution quality"
execution:
backend-engineer:
type: ephemeral
context-loading: agent-software-controlled
task: "Implement API endpoints per spec"
tester:
type: ephemeral
context-loading: agent-software-controlled
task: "Run test suite, return pass/fail"
waves:
wave-1: [backend-engineer, tester] # parallel
checkpoint: architect-agent # gate
wave-2: [code-reviewer] # sequentialThis is not a production schema. It is a thinking tool. Notice how the config captures the four decisions from this chapter: agent versus subagent (type), context loading mode (context-loading), governance versus execution separation (the two sections), and architecture pattern (waves). The orchestrator doesn't need to be complex. It needs to be deliberate.
That config captures the plan. But plans fail.
When Plans Fail: Adaptive Replanning and Rollback
At TechLok, Team 1's Bluetooth solution worked technically but failed on user experience. We didn't scrap the project or retry the same approach. We replanned. We took the working mechanism and paired it with a better trigger. That instinct to adapt rather than abandon is what separates orchestrated systems from brittle ones.
Real orchestration handles failure, not just success. Chapter 7 defined checkpoint gates where work pauses for validation. But what happens when an agent's plan fails mid-execution?
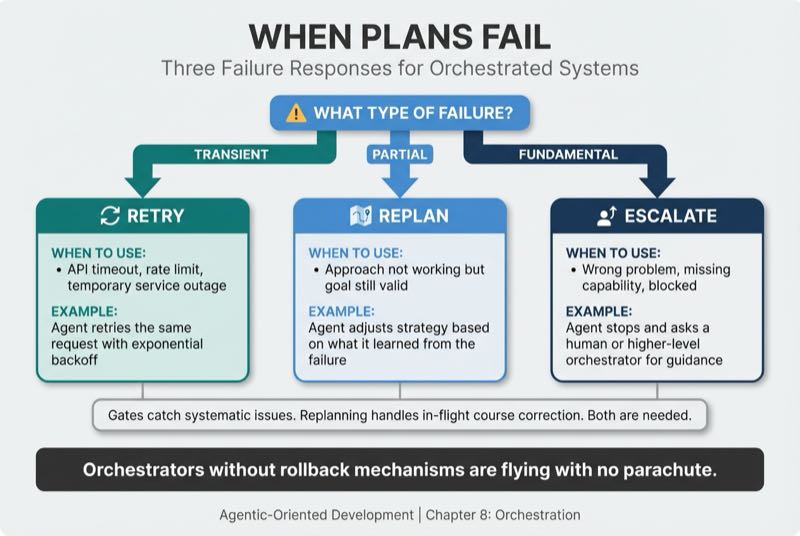
I find it useful to think about failure in three categories.
| Response | When to Use | Example |
|---|---|---|
| Retry | Transient failure like API timeout or rate limit | Agent retries the same request with backoff |
| Replan | Partial failure where approach isn't working but goal is still valid | Agent adjusts strategy based on what it learned from the failure |
| Escalate | Fundamental failure like wrong problem or missing capability | Agent stops and asks a human or higher-level orchestrator for guidance |
Checkpoint gates from Chapter 7 handle stop-and-review. The spec defines gates where work pauses for validation. Adaptive replanning handles adjust-and-continue. The agent or orchestrator recognizes the current approach is failing and adjusts without stopping the whole workflow.
Both are needed. Gates catch systematic issues. Replanning handles in-flight course correction.
Rollback mechanisms matter when agents act on external systems. Git handles code rollback. But agents also make API calls, deployments, and database changes. For these actions, you need explicit undo patterns. Saga patterns give each step a corresponding compensating action. Idempotent operations make retrying safe because the same action always produces the same result. If an agent creates a cloud resource, the rollback must destroy that resource. Deleting the reference in code is not enough.
Orchestrators without rollback mechanisms are flying with no parachute. The higher the stakes, the more important the undo pattern.
Start Here: The Orchestration Checklist
If you are designing an agent system, work through these five decisions in order. Each one builds on the previous.
List your roles. Identify every role in the workflow. PM, Architect, Team Lead, Backend-Engineer, Tester, Security-Analyst, whatever your project needs.
Classify each role: Remember or Execute? Governance roles that carry context across phases are agents. Execution roles scoped to a single task are subagents.
Assign a context loading mode to each role. LLM-controlled for exploratory work where you trust the agent. Agent-software-controlled for compliance-critical tasks where context must be deterministic. Human-controlled for sensitive decisions where a human should stay in the loop.
Choose your architecture pattern. Sequential when phases depend on each other. Hierarchical plus parallel when tasks are independent but need a coordination point. Start with agentic workflows (orchestrated with checkpoints), not fully autonomous agents.
Define your failure responses. For each agent, decide what happens when things go wrong. Retry for transient failures. Replan for partial failures. Escalate for fundamental ones. If agents touch external systems, define explicit rollback steps. And for any orchestrated system, ensure structured logging at the orchestrator level so you can trace subagent outputs when things go wrong.
These five decisions are the foundation of any orchestrated system. Get them right and the rest is implementation.

What's Next
TechLok succeeded because the orchestrator designed composition, not just coordination. I chose who ran in parallel, decided what each team should explore, and combined the strongest pieces into something none of us could have built alone.
But coordinating specialists only matters if you can tell good output from bad. Chapter 9 covers Evals and Loops, where evaluation becomes control flow, not just quality checking. The agents who build also need agents who judge.
The orchestrator's real job was never coordination. It was seeing the combination no one else could.